
What is Data Annotation | Is Data Annotation Tech Legit | Complete Guide
The phrase “data is the new oil” captures the profound importance of data in the field of artificial intelligence (AI). Similar to how oil drives economies and industries, data drives AI algorithms. To be truly valuable, raw data must be refined and properly labeled to ensure AI algorithm’s accuracy and relevance. Therefore, the process of getting data ready to fuel various Machine Learning Algorithms is intricate. In particular, the first stage for training any Computer Vision model involves providing it with well-refined, preprocessed, and labeled data.
This post will guide you through the evolution of data annotation tools and techniques, helping you identify the best tools suited for labeling your data effectively.
In this post we’ll cover the following:
- What is Data Annotation?
- Is Data Annotation Legit?
- Why does data annotation matter?
- Types of Data Annotation
- Evolution of Data Annotation
- Is Data Annotation Tech Legit?
- Tools and Software for Data Labeling and Annotation
What is Data Annotation?
Data annotation in computer vision refers to the process of labeling data, such as images or videos, with metadata or tags that describe the objects, attributes, or actions present in the data. This labeling is typically done manually by human annotators or can be automated using machine learning algorithms. The annotated data serves as a training set for machine learning models, enabling them to learn and recognize patterns, objects, or features within the data. Annotation can include labeling objects in images (object detection), outlining shapes (image segmentation), identifying keypoints (pose estimation), or tagging actions in videos (action recognition), among other tasks. The quality and accuracy of data annotation significantly impact the performance and reliability of computer vision models.
Is Data Annotation Legit?
Yes, data annotation is a legitimate practice integral to various fields, particularly machine learning and artificial intelligence. It involves labeling or tagging data with relevant information, enabling supervised learning algorithms to learn from examples and make accurate predictions. Data annotation tasks encompass labeling images, text, audio, or video data with categories or attributes. Ensuring the quality and consistency of annotations is crucial for the efficacy of machine learning models, whether performed by specialized service providers or in-house teams.
Looking for data annotation services? Contact Us.
Why Does Data Annotation Matter?
Machines cannot directly perceive images and videos as humans do. Data annotation makes different data types machine-readable. It adds contextual information and labels to data, specifically images and videos, making it more understandable and usable for AI algorithms. Without this critical step, AI systems would struggle to extract meaningful insights and deliver optimal results. Moreover, the performance and accuracy of AI models depend on the quality and quantity of annotated data. Here is why it matters:
Critical Applications:
Annotated Data is the lifeblood of machine learning algorithms. Machine learning models are used in critical applications such as healthcare, security and surveillance. Erroneous AI/ML models can be dangerous, so high-quality annotated data is essential.
Supervised Learning:
In supervised machine learning, labeled datasets are crucial. ML models need to understand input patterns to process them and produce accurate results. Examples:
Classification:
Assigning test data into specific categories (e.g., predicting whether a patient has a disease).
Regression:
Establishing relationships between dependent and independent variables (e.g., estimating the relationship between advertising budget and product sales)
Types of Data Annotation:
The term “data annotation” refers to a broad range of approaches and procedures for labeling data in machine learning applications. These are a few typical categories of data annotation used by annotators depending on the task and model requirements.
1. Bounding Box Annotation:

This type of annotation involves drawing rectangles (bounding boxes) around objects of interest in images or videos. It’s commonly used for object detection tasks, where the model needs to localize and recognize objects within an image.
2. Polygon Annotation:

Polygon annotation is similar to bounding boxes but involves drawing more complex shapes (polygons) around objects with irregular boundaries. It’s often used for precise object delineation, such as segmenting buildings, roads, or natural objects like trees and rivers.
3. Semantic Segmentation:
 In semantic segmentation, each pixel in an image is labeled with a class or category. This technique is used to segment images into meaningful parts, such as identifying different objects or regions within an image. It’s valuable for tasks like medical image analysis, scene understanding, and image editing.
In semantic segmentation, each pixel in an image is labeled with a class or category. This technique is used to segment images into meaningful parts, such as identifying different objects or regions within an image. It’s valuable for tasks like medical image analysis, scene understanding, and image editing.
4. Instance Segmentation:
 Instance segmentation is an extension of semantic segmentation where individual instances of objects are labeled separately. It not only identifies object categories but also distinguishes between multiple instances of the same object class. Instance segmentation is crucial for applications requiring precise object identification and counting, such as counting cells in microscopy images.
Instance segmentation is an extension of semantic segmentation where individual instances of objects are labeled separately. It not only identifies object categories but also distinguishes between multiple instances of the same object class. Instance segmentation is crucial for applications requiring precise object identification and counting, such as counting cells in microscopy images.
5. Keypoint Annotation:
 Keypoint annotation involves labeling specific points or landmarks on objects within an image. For example, in human pose estimation, keypoints are annotated on body joints like shoulders, elbows, and knees. This annotation type helps AI models understand spatial relationships and pose configurations.
Keypoint annotation involves labeling specific points or landmarks on objects within an image. For example, in human pose estimation, keypoints are annotated on body joints like shoulders, elbows, and knees. This annotation type helps AI models understand spatial relationships and pose configurations.
6. Text Annotation:
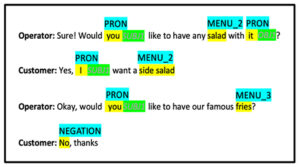
Text annotation involves labeling text data for tasks like named entity recognition (NER), sentiment analysis, or text classification. Annotators mark entities such as names, locations, dates, and sentiment expressions within text documents to train models to extract meaningful information.
7. Video Annotation:
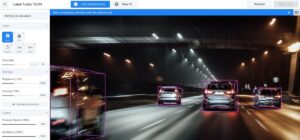 This is temporal annotation used for annotating time-based data, such as videos or audio recordings. It involves labeling actions, events, or speech segments over time. For example, in video analysis, annotators label activities, gestures, or interactions between objects in sequential frames.
This is temporal annotation used for annotating time-based data, such as videos or audio recordings. It involves labeling actions, events, or speech segments over time. For example, in video analysis, annotators label activities, gestures, or interactions between objects in sequential frames.
8. 3D Annotation:
 3D annotation is used for annotating three-dimensional data, such as point clouds from LiDAR sensors or 3D models from computer-aided design (CAD) software. It involves labeling objects in 3D space, such as buildings, vehicles, or terrain features, and is essential for applications like autonomous driving and augmented reality.
3D annotation is used for annotating three-dimensional data, such as point clouds from LiDAR sensors or 3D models from computer-aided design (CAD) software. It involves labeling objects in 3D space, such as buildings, vehicles, or terrain features, and is essential for applications like autonomous driving and augmented reality.
Evolution of Data Annotation:
Manual Data Labeling:
Manual data annotation and labeling is the traditional way that organizations label data. It involves humans carefully tagging and sorting data based on specific instructions. Humans are good at understanding context, details, and complex patterns, which makes manual labeling accurate. However, this method is slow, requires a lot of effort, and can sometimes have mistakes due to human errors. Despite these challenges, manual labeling is crucial for tasks where human judgment is important, like in healthcare, finance, and autonomous driving. Technology has also improved, giving us semi-automated and fully automated labeling tools that are faster and scalable, but they still rely on human expertise for certain tasks.
Here’s a detailed analysis of its strengths and limitations:
Strengths:
a.Accuracy and Precision:
Manual data labeling often results in high accuracy and precision, as human annotators can understand context, nuances, and complex patterns better than machines. This leads to accurate annotations that are contextually relevant and meaningful.
b.Contextual Understanding:
Human annotators can apply domain expertise and contextual understanding to ensure relevant and accurate annotations. This is particularly valuable in tasks where subjective judgment or specialized knowledge is required.
c.Flexibility:
Manual labeling offers flexibility in adapting to changing annotation criteria or guidelines during the labeling process. Annotators can adjust their approach based on the specific requirements of the task or dataset, leading to customized and tailored annotations.
d.Handling Complexity:
Manual labeling is well-suited for handling complex or ambiguous data points that may be challenging for automated systems. Human annotators can navigate intricate details, irregular shapes, or subtle variations in data, ensuring comprehensive annotations.
e.Quality Assurance:
Manual data labeling allows for rigorous quality assurance checks, as annotators can review, validate, and adjust annotations to ensure accuracy and consistency. This hands-on approach contributes to the overall quality of the labeled dataset.
Limitations:
a. Time-Consuming:
Manual data labeling is a time-intensive process, especially for large datasets. The manual effort required can lead to slower turnaround times and delays in the data preparation pipeline.
b. Labor-Intensive:
It requires a significant amount of human effort and resources, leading to increased operational costs and manpower requirements. This can be a cost-prohibitive factor for organizations with limited resources or budgets.
c. Human Error:
Manual data labeling is susceptible to human error, fatigue, or inconsistency among annotators, which can result in inaccuracies in the labeled data. Maintaining consistency and reliability across annotations can be challenging.
d. Scalability Challenges:
Manual labeling processes may struggle to scale efficiently with the increasing volume of data over time. Handling large-scale annotation projects can pose scalability challenges and require additional resources.
e. Subjectivity:
Manual annotation introduces subjective biases or interpretations, especially in tasks requiring subjective judgment or interpretation. Ensuring consistency and objectivity across annotations can be a complex task.
Semi Automated Data Labelling:
Semi-automated data labeling techniques combine the strengths of manual annotation with the efficiency of automation, offering a balanced approach to data labeling. This method leverages human annotators’ expertise while utilizing automation tools and algorithms to streamline the labeling process. Here’s a complete analysis of semi-automated data labeling techniques:
Efficiency:
One of the primary benefits of semi-automated data labeling is increased efficiency compared to purely manual methods. Automation tools can assist annotators by suggesting labels, pre-labeling data based on patterns or rules, or providing semi-automated segmentation for complex objects. This reduces the manual effort required and speeds up the overall labeling process, leading to faster turnaround times for annotated datasets.
Accuracy:
Semi-automated techniques aim to maintain a high level of accuracy by combining human judgment with automated assistance. While automation can help with repetitive tasks and reduce human error, human annotators still play a crucial role in verifying and correcting annotations to ensure accuracy. This hybrid approach minimizes the risk of inaccuracies that may arise from purely automated labeling methods.
Scalability:
Semi-automated data labeling techniques are well-suited for scalable annotation projects. The combination of human expertise and automation allows organizations to handle large volumes of data more efficiently. Automation tools can handle repetitive tasks and assist in scaling the labeling process to accommodate growing datasets without significantly increasing manpower or resources.
Cost-Effectiveness:
While semi-automated data labeling may involve initial investment in automation tools and technology, it can lead to long-term cost savings. The efficiency gains and reduced manual effort translate to lower operational costs over time, especially for organizations dealing with large-scale annotation tasks.
Complexity Handling:
Semi-automated techniques excel in handling complex data labeling tasks. Automation tools can assist in segmenting complex objects, identifying patterns in data, or suggesting labels based on predefined rules. This is particularly beneficial in tasks such as image segmentation, where automation can accelerate the labeling of intricate object boundaries.
Human Oversight:
Despite the automation involved, semi-automated data labeling maintains human oversight and control. Annotators can review, validate, and adjust automated annotations as needed, ensuring the quality and accuracy of the labeled dataset. This human-in-the-loop approach enhances the reliability of the annotated data for training machine learning models.
Adaptability:
Semi-automated labeling techniques are adaptable to different types of data and annotation tasks. Whether it’s image labeling, text annotation, or video analysis, automation tools can be customized or configured to suit specific labeling requirements and annotation guidelines. This adaptability makes semi-automated techniques versatile across various domains and applications.
Challenges:
Despite its advantages, semi-automated data labeling may face challenges in certain scenarios. Integration and compatibility issues with existing data infrastructure or annotation platforms can pose initial implementation challenges. Ensuring seamless collaboration between automation tools and human annotators also requires effective communication and training.
Fully Automated Data Labelling:
Fully automated data labeling techniques have indeed revolutionized data annotation processes, offering significant advantages in speed, consistency, and cost savings. Here’s a detailed analysis of the benefits and considerations associated with fully automated data labelling:
Benefits:
a. Speed and Efficiency:
One of the most significant advantages of fully automated data labeling is its speed and efficiency. Automated systems can process large volumes of data at a fraction of the time it would take human annotators. This accelerated labeling process speeds up data preparation, model training, and deployment, allowing organizations to iterate and innovate faster.
b. Consistency and Accuracy:
Automated systems follow predefined rules and guidelines with precision, ensuring consistent labeling across all data points. This consistency improves the accuracy and reliability of machine learning models trained on the labeled data, leading to more robust AI applications with fewer errors.
c. Cost Savings:
Automation reduces costs associated with manual labor, as fewer human resources are needed for the labeling task. This cost savings can be significant for organizations dealing with large-scale annotation projects or tight budgets, allowing them to allocate resources more efficiently.
d. Scalability:
Fully automated data labeling techniques are highly scalable, capable of handling diverse types of data and large datasets efficiently. This scalability is crucial for organizations with growing data volumes or fluctuating annotation needs, as automated systems can adapt to changing demands without compromising speed or accuracy.
e. Versatility:
Automated systems can process various types of data, including text, images, audio, and video formats, providing versatile solutions for businesses with diverse data annotation requirements. This versatility makes fully automated data labeling suitable for a wide range of industries and use cases.
Considerations:
a. Data Complexity:
While automated systems excel in handling large volumes of data, they may struggle with highly complex or nuanced labeling tasks. Tasks requiring subjective judgment, fine-grained annotations, or intricate object delineation may still require human intervention or verification to ensure accuracy.
b. Training and Maintenance:
Fully automated data labeling systems require initial training and ongoing maintenance to ensure optimal performance. This includes training machine learning algorithms, fine-tuning labeling rules, and monitoring system accuracy over time. Organizations need to invest in expertise and resources to manage and maintain automated labeling systems effectively.
c.Edge Cases and Ambiguity:
Automated systems may encounter challenges with edge cases, ambiguous data points, or rare patterns that are not covered by predefined rules. Human oversight or intervention may be necessary to handle these cases and prevent errors in labeling.
d.Bias and Fairness:
Automated labeling systems can inherit biases from training data or predefined rules, potentially leading to biased annotations. Organizations must implement measures to detect and mitigate biases in automated labeling processes to ensure fairness and equity in AI applications.
Comparison of Manual, Semi-Automated, and Fully Automated Data Labeling:
To summarize, fully automated data labeling is superior in terms of speed, consistency, and cost savings, but it also necessitates careful consideration of bias mitigation and data complexity. Although manual data labeling is very accurate and flexible, it is expensive and time-consuming for large-scale projects. Semi-automated data labeling is a compelling option for businesses looking for scalable and affordable data annotation solutions because it strikes a balance between accuracy and efficiency by utilizing human expertise while gaining the benefits of automation. Organizations can select the best data labeling method for AI-driven applications by knowing the advantages and disadvantages of each approach and how it best fits their needs.
Is Data Annotation Tech Legit?
Yes, data annotation technology is legitimate. It refers to the tools and software used to facilitate the process of labeling or tagging data with relevant information, making it usable for training machine learning models. These technologies can include annotation platforms, software applications, or frameworks designed to streamline and automate the data annotation process.
Tools and Software for Data Labeling and Annotation:
In order to prepare data for AI and machine learning models, data labeling tools are crucial. The following are a few of the best software programs and tools for data labeling:
A) SuperAnnotate:
SuperAnnotate, ranked as the best data labeling platform on G2, offers a comprehensive solution with features like image, video, and text annotation software, AI data management and curation tools, integrations with storage solutions, MLOps support, and project and quality management capabilities.
B) Labelbox:
Labelbox is a versatile data labeling platform that supports image, video, and text annotation. It offers various annotation types, quality assurance for accurate annotations, customization options, and integration with other tools and services.
C) Amazon SageMaker Ground Truth:
Amazon SageMaker Ground Truth is a managed service designed for data labeling within the AWS ecosystem. It supports annotation for images, videos, and text data, offering versatility in labeling tasks. The service seamlessly integrates with other AWS services, facilitating a streamlined workflow. Additionally, SageMaker Ground Truth provides automation tools to enhance labeling efficiency and productivity.
D) CVAT (Computer Vision Annotation Tool):
CVAT (Computer Vision Annotation Tool) is an open-source platform designed for annotating images and videos. Its features include various annotation types such as bounding boxes, polygons, and keypoints, making it versatile for different labeling needs. CVAT supports collaboration with multiple annotators, offers customization options, and is extendable for additional functionalities. With an active community contributing to regular updates and improvements, CVAT remains a reliable choice for computer vision annotation tasks.
E) Label Studio:
Label Studio is an open-source data labeling tool known for its user-friendly interface. It supports a variety of annotation types, including text, image, and audio annotation. The tool offers customizable workflows, allowing users to define their own annotation tasks based on project requirements. Additionally, Label Studio facilitates integration with existing pipelines, making it easy to incorporate into existing workflows and data processing pipelines.
F) Roboflow:
Roboflow Annotate is a robust data annotation tool for computer vision projects, offering automated labeling with AI assistance, fast labeling workflows with keyboard shortcuts and intelligent defaults, real-time collaboration features for teams, format flexibility, and integration capabilities. Its managed labeling service ensures scalability and high-quality results, making it an efficient and collaborative choice for data annotation needs.
G) VGG Image Annotator (VIA):
VGG Image Annotator (VIA) is a lightweight and web-based annotation tool designed for basic annotation tasks. Its simple interface makes it easy to use, while it also supports region-based annotation for image segmentation tasks. VIA allows users to export annotations in various formats, enhancing flexibility and compatibility with different platforms and tools.
H) V7:
V7 is a data labeling tool that specializes in image and video annotation, offering features such as bounding boxes and keypoint annotations. It stands out for its strong emphasis on quality control and accuracy in annotations. However, it has a smaller user base compared to some other tools in the market.
Conclusion:
In conclusion, manual to AI-driven approaches have emerged in the evolution of data annotation, each with unique benefits and difficulties. Although manual labeling is labor- and time-intensive, it offers accuracy and contextual understanding. Semi-automated labeling maximizes accuracy and efficiency by fusing automation and human knowledge. Although fully automated labeling is fast and scalable, bias mitigation and data complexity must be carefully taken into account. The best strategy will depend on a number of variables, including the demands of the project, the need for scalability, and financial limitations. SuperAnnotate, Labelbox, and Amazon SageMaker Ground Truth are just a few of the tools that make data labeling for AI and machine learning projects more effective.
Are you in need of high-quality data annotation services? Look no further! Our team specializes in accurate and efficient data labeling for various applications. Whether you require image, text, audio, or video annotation, we’ve got you covered. Contact us today to discuss your project requirements and let us help you unlock the full potential of your data!