
Hardware Accelerators : A Comprehensive Guide
Our computers are similar to a bicycle that is trying to climb up the steep hill of data. It’s slow, it struggles, and it can’t handle heavy loads. It needs a very powerful engine to climb. Hardware accelerators serve as a turbo boost for our CPUs and computers to encourage massive processing and computation swiftly.
What’s in this Guide?
In today’s rapidly evolving technological landscape, the convergence of artificial intelligence (AI) and hardware acceleration has emerged as a game-changer. From model deployment to real-time inference, AI-hardware accelerators are pivotal in enhancing the efficiency and performance of AI applications across diverse domains. This comprehensive guide delves deeper into the technical aspects, practical applications, and benefits of AI-hardware accelerators, focusing on deployment kits, development boards, edge devices, and GPUs.
What are Hardware Accelerators?
A hardware accelerator is a specialised component or subsystem within an edge device that is dedicated to accelerating specific computations, such as AI inferencing, image processing, video encoding and decoding, cryptography, and more. By leveraging hardware accelerators, edge devices can perform complex computations faster, reduce latency, conserve energy, and enhance overall performance. Here are some common types of hardware accelerators and their frameworks and applications.

Hardware Accelerator |
Applications |
Technical Details |
Frameworks Support |
GPU |
Computer Graphics, General-Purpose Computing, AI Training/Inference, Ray Tracing, Video Processing. |
|
CUDA, OpenCL, TensorFlow, PyTorch, Caffe |
TPU |
Machine Learning, Neural Networks, AI Acceleration. |
|
TensorFlow, TensorFlow Lite, TensorFlow Extended |
NPU |
AI Inference, Edge Computing. |
|
TensorFlow, PyTorch, ONNX |
FPGA |
Custom Hardware Acceleration, Reconfigurable Computing. |
|
Intel OpenCL SDK, Xilinx Vivado, Apache OpenCL |
SoC |
Embedded Systems, IoT Devices |
|
TensorFlow Lite, PyTorch Mobile, Edge TPU |
DSP |
Digital Signal Processing, Audio Processing |
|
MATLAB, Simulink, C/C++ |
ASIC’s |
Cryptography, AI Acceleration |
|
TensorFlow, PyTorch, FPGA Libraries |
VPU |
Vision Processing, Edge AI |
|
OpenCV, TensorFlow Lite, PyTorch Mobile |
DPU |
Data Processing, Networking Acceleration |
|
TensorFlow, PyTorch, ONNX, DPDK |
MPU |
Motion Processing, Robotics |
|
ROS, MATLAB Robotics System Toolbox |
QPU |
Quantum Computing, Quantum Simulation |
|
Qiskit, Cirq, QuTiP, Microsoft Q# |
How do Hardware Accelerators Work?
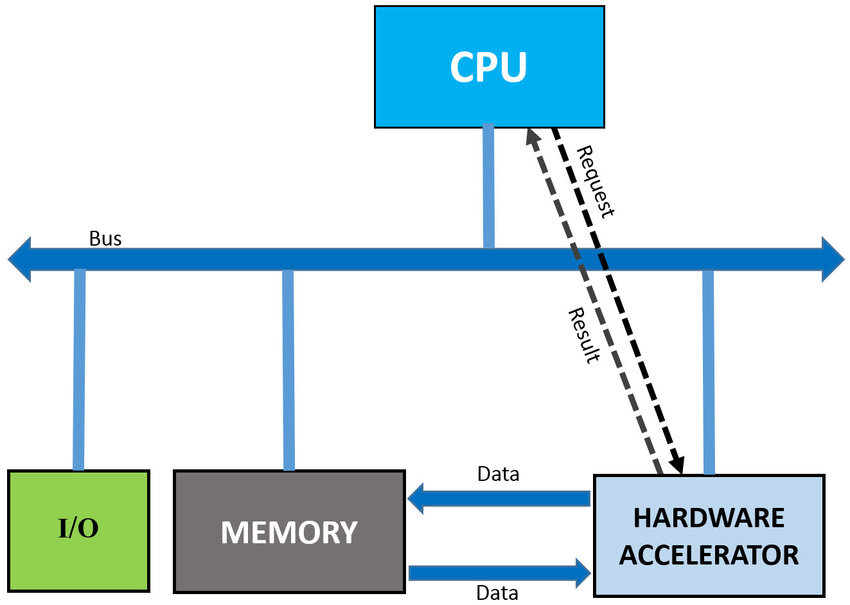
CPU Offload to Hardware Accelerator (FPGA). Image source:ResearchGate.
Hardware acceleration refers to the process of shifting computing tasks from a general-purpose processor (CPU) to specialised hardware accelerators, such as field-programmable gate arrays (FPGAs) or application-specific integrated circuits (ASICs). This offload occurs because these hardware accelerators are optimised for specific tasks, making them faster and more efficient at performing those tasks compared to a CPU.
In an FPGA-based hardware accelerator architecture, the CPU communicates with the FPGA through a high-speed interface such as PCIe (Peripheral Component Interconnect Express) or AXI (Advanced eXtensible Interface).
Once an FPGA receives a task, it organises its internal logic circuits, called programmable logic blocks, to execute the task in parallel. FPGAs excel in parallel processing because of their reconfigurability, allowing them to perform multiple calculations simultaneously.
After completing the calculation, the FPGA sends the result back to the interface CPU, which has the highest speed. The FPGA’s ability to process tasks in parallel and its unique design allow it to perform tasks faster than a CPU, resulting in faster processing and reduced latency
Overall, hardware accelerations use special hardware accelerators such as FPGAs to offload specific tasks from the CPU, resulting in faster and more efficient computation, especially for tasks that require high parallelism or specialised algorithms.
Benefits of Hardware Accelerators:
In the domain of AI, edge computation serves as a cornerstone in facilitating instantaneous data processing and decision-making at the network’s periphery, in close proximity to the data’s origin. Especially in computer vision, the workloads are high, and the tasks to be computed are highly data-intensive. Therefore, using AI hardware acceleration for edge devices has many advantages, including:
Speed and Efficiency:
AI accelerators significantly enhance the speed and performance of AI tasks such as model deployment, computer vision, and real-time inference on edge devices. They enable quicker processing of data, reducing latency, and enabling real-time use cases.
Promising Data Security and Privacy:
By processing critical data locally on edge devices using AI accelerators, the need to transmit sensitive information across different systems is minimized. This enhances security and allows for stricter user access control on edge devices, particularly in applications involving sensitive information like surveillance or healthcare.
Scalability:
Edge devices equipped with AI accelerators can scale without performance limitations. This scalability factor enables businesses to start with minimal costs and expand their AI capabilities as needed, leveraging deployment kits and development boards for efficient scaling.
Reliability:
AI accelerators facilitate distributed processing and storage across edge devices, reducing the impact of potential disruptions such as cyberattacks, DDoS attacks, or power outages. This distributed architecture enhances network resilience and reliability.
Off-net Capabilities:
Edge-based systems powered by AI accelerators can operate even in environments with limited network connectivity, ensuring continuity for mission-critical systems that require real-time processing.
Popular Deployment Kits and Development Boards:
Selecting the right edge device for model deployment is an uphill battle in computer vision and natural language processing (NLP) tasks. Here is a comprehensive comparison to guide you on the best edge device options to consider in 2024 that better suit your needs and requirements.
AI Performance:
Development Board |
Manufacturer |
AI Performance |
| Raspberry Pi 3B+ | Raspberry Pi Ltd. | – |
| Raspberry Pi 4B | – | |
| Raspberry Pi 5 | – | |
| Google Coral | coral.ai | 4TOPS |
| Google Coral Mini | ||
| Google Coral Micro | ||
| Google SoM | ||
| Jetson AGX Orin 64GB |
NVIDIA |
275 TOPS |
| Jetson AGX Orin Industrial | 248 TOPS | |
| Jetson AGX Orin 32GB | 200 TOPS | |
| Jetson Orin NX 16GB | 100 TOPS | |
| Jetson Orin NX 8GB | 70 TOPS | |
| Jetson Orin Nano 8GB | 40 TOPs | |
| Jetson Orin Nano 4GB | 20 TOPs | |
| Jetson AGX Xavier Industrial | 30 TOPS | |
| Jetson AGX Xavier 64GB | 32 TOPS | |
| Jetson AGX Xavier | ||
| Jetson Xavier NX 16GB | 21 TOPS | |
| Jetson Xavier NX | ||
| Jetson TX2i | 1.26 TFLOPS | |
| Jetson TX2 | 1.33 TFLOPS | |
| Jetson TX2 4GB | ||
| Jetson TX2 NX | ||
| Jetson Nano | 472 GFLOPS |
GPU, CPU AND RAM:
Development Board |
GPU Memory |
RAM |
Storage |
| Raspberry Pi 3B+ | Broadcom Videocore-IV | 1GB LPDDR2 SDRAM | MicroSD card slot |
| Raspberry Pi 4B | Broadcom VideoCore VI | 2GB/4GB/8GB LPDDR4 SDRAM | MicroSD card slot |
| Raspberry Pi 5 | Not applicable (Direct RAM access) | Varies (8GB available) | MicroSD card slot |
| Google Coral | Edge TPU (ML accelerator) | 1GB LPDDR4 RAM | 8GB eMMC storage |
| Google Coral Mini | Edge TPU (ML accelerator) | 2GB LPDDR4 RAM | 8GB eMMC storage |
| Google Coral Micro | Edge TPU (ML accelerator) | 1GB LPDDR4 RAM | 8GB eMMC storage |
| Google SoM | Edge TPU (ML accelerator) | 8GB LPDDR4 RAM | 64GB eMMC storage |
| Jetson AGX Orin 64GB | NVIDIA Orin GPU | 64GB LPDDR4x RAM | 32GB eMMC storage |
| Jetson AGX Orin Industrial | NVIDIA Orin GPU | 64GB LPDDR4x RAM | 32GB eMMC storage |
| Jetson AGX Orin 32GB | NVIDIA Orin GPU | 32GB LPDDR4x RAM | 32GB eMMC storage |
| Jetson Orin NX 16GB | NVIDIA Orin GPU | 16GB LPDDR4x RAM | 16GB eMMC storage |
| Jetson Orin NX 8GB | NVIDIA Orin GPU | 8GB LPDDR4x RAM | 16GB eMMC storage |
| Jetson Orin Nano 8GB | NVIDIA Orin GPU | 8GB LPDDR4x RAM | MicroSD card slot |
| Jetson Orin Nano 4GB | NVIDIA Orin GPU | 4GB LPDDR4x RAM | MicroSD card slot |
| Jetson AGX Xavier Industrial | NVIDIA Xavier GPU | 32GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson AGX Xavier 64GB | NVIDIA Xavier GPU | 64GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson AGX Xavier | NVIDIA Xavier GPU | 16GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson Xavier NX 16GB | NVIDIA Xavier GPU | 16GB LPDDR4 RAM | MicroSD card slot |
| Jetson Xavier NX | NVIDIA Xavier GPU | 8GB LPDDR4 RAM | MicroSD card slot |
| Jetson TX2i | NVIDIA Pascal GPU | 8GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson TX2 | NVIDIA Pascal GPU | 8GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson TX2 4GB | NVIDIA Pascal GPU | 4GB LPDDR4 RAM | 32GB eMMC storage |
| Jetson TX2 NX | NVIDIA Pascal GPU with 256 CUDA cores | 4GB 128-bit LPDDR4, 1600 MHz | 16GB eMMC 5.1 Flash Storage |
| Jetson Nano | NVIDIA Maxwell architecture with 128 CUDA cores | 4GB 64-bit LPDDR4, 1600MHz | 16GB eMMC 5.1 |
Connectivity, Cost, Scalability and Power:
DevelopmentBoard |
Connectivity |
Cost (Approx.) |
Scalability |
Power |
| Raspberry Pi 3B+ | Gigabit Ethernet, Wi-Fi | $35 | Limited | 5V/2.5A DC via micro USB connector |
| Raspberry Pi 4B | Gigabit Ethernet, Wi-Fi, Bluetooth | Starting from $35 | Moderate | 5V DC via USB-C connector (minimum 3A) |
| Raspberry Pi 5 | Gigabit Ethernet, Wi-Fi, Bluetooth | Varies based on RAM | High | 5V/5A DC via USB-C |
| Google Coral | USB, Wi-Fi | $75 | Limited | – |
| Google Coral Mini | USB, Wi-Fi | $99 | Limited | – |
| Google Coral Micro | USB | $25 | Limited | – |
| Google SoM | USB, Wi-Fi | Varies | High | – |
| Jetson AGX Orin 64GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $1,099 | High | 15W – 60W |
| Jetson AGX Orin Industrial | Gigabit Ethernet, Wi-Fi, Bluetooth | Varies | High | 15W – 75W |
| Jetson AGX Orin 32GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $899 | High | 15W – 40W |
| Jetson Orin NX 16GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $399 | Moderate | 10W – 25W |
| Jetson Orin NX 8GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $349 | Moderate | 10W – 20W |
| Jetson Orin Nano 8GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $199 | Limited | 7W – 15W |
| Jetson Orin Nano 4GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $129 | Limited | 7W – 10W |
| Jetson AGX Xavier Industrial | Gigabit Ethernet, Wi-Fi, Bluetooth | Varies | High | 20W – 40W |
| Jetson AGX Xavier 64GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $1,099 | High | 10W – 30W |
| Jetson AGX Xavier | Gigabit Ethernet, Wi-Fi, Bluetooth | $699 | High | |
| Jetson Xavier NX 16GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $399 | Moderate | 10W – 20W |
| Jetson Xavier NX | Gigabit Ethernet, Wi-Fi, Bluetooth | $349 | Moderate | |
| Jetson TX2i | Gigabit Ethernet, Wi-Fi, Bluetooth | $399 | Moderate | 10W – 20W |
| Jetson TX2 | Gigabit Ethernet, Wi-Fi, Bluetooth | $399 | Moderate | 7.5W – 15W |
| Jetson TX2 4GB | Gigabit Ethernet, Wi-Fi, Bluetooth | $399 | Moderate | |
| Jetson TX2 NX | Gigabit Ethernet | $699 | High | |
| Jetson Nano | Gigabit Ethernet | $99 | Moderate | 5W – 10W |
Software Frameworks and Programming Languages:
DevelopmentBoard |
Software Frameworks |
Programming Languages |
| Raspberry Pi 3B+ | Raspbian, Ubuntu, Windows 10 IoT Core | Python, C/C++, Scratch |
| Raspberry Pi 4B | Raspbian, Ubuntu, Windows 10 IoT Core | Python, C/C++, Scratch |
| Raspberry Pi 5 | Raspbian, Ubuntu, Windows 10 IoT Core | Python, C/C++, Scratch |
| Google Coral | TensorFlow Lite, Edge TPU API | Python, C++ |
| Google Coral Mini | TensorFlow Lite, Edge TPU API | Python, C++ |
| Google Coral Micro | TensorFlow Lite, Edge TPU API | Python, C++ |
| Google SoM | TensorFlow Lite, Edge TPU API | Python, C++ |
| Jetson AGX Orin 64GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson AGX Orin Industrial | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson AGX Orin 32GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson Orin NX 16GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson Orin NX 8GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson Orin Nano 8GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson Orin Nano 4GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson AGX Xavier Industrial | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson AGX Xavier 64GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson AGX Xavier | NVIDIA Linux for Tegra® driver package, including Ubuntu-derived sample file system | AI, Compute, Multimedia, and Graphics libraries and APIs (Refer to NVIDIA documentation for current support) |
| Jetson Xavier NX 16GB | NVIDIA Linux for Tegra® driver package, cloud-native support, pre-trained AI models from NVIDIA NGC and the TAO Toolkit | AI, Compute, Multimedia, and Graphics libraries and APIs (Supports all popular AI frameworks) |
| Jetson Xavier NX | NVIDIA Linux for Tegra® driver package, cloud-native support, pre-trained AI models from NVIDIA NGC and the TAO Toolkit | AI, Compute, Multimedia, and Graphics libraries and APIs (Supports all popular AI frameworks) |
| Jetson TX2i | NVIDIA Linux for Tegra® driver package | AI, Compute, Multimedia, and Graphics libraries and APIs (Refer to NVIDIA documentation for current support) |
| Jetson TX2 | NVIDIA Linux for Tegra® driver package | AI, Compute, Multimedia, and Graphics libraries and APIs (Refer to NVIDIA documentation for current support) |
| Jetson TX2 4GB | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson TX2 NX | NVIDIA JetPack, TensorRT | Python, C++, CUDA |
| Jetson Nano | TensorFlow, PyTorch, Caffe, Keras, OpenCV, ROS | Python, C++ |
Recommendations:
Based on the extensive analysis offered in the article, I would propose using specific edge devices for various project scopes and requirements. For large-scale AI applications with complicated models and demanding calculations, I strongly advise using high-performance edge devices like the NVIDIA Jetson AGX Xavier or Google Coral Dev Board. These boards come with powerful AI accelerators that enable quick model deployment, rapid real-time inference, and seamless integration with AI frameworks such as TensorFlow and PyTorch. On the other hand, for smaller AI installations or development, less expensive solutions like the Raspberry Pi 4B or the NVIDIA Jetson Nano provide adequate computational power and flexibility. Furthermore, for edge computing applications in IoT contexts or embedded systems, the Raspberry Pi 3B offers cost-effective solutions with enough processing power.
To achieve the best performance and efficiency, the edge device’s hardware specifications and functionality must be compatible with the project’s computational requirements and deployment environment.
Conclusion:
This guide explains why hardware accelerators are required alongside their applications. Because in the fast-paced world of AI, you need every advantage possible. They’re the magic ingredient that makes your AI visions come to life, reducing effort and consuming less energy in the process.
To sum up, hardware accelerators, such as GPUs, are revolutionising AI capabilities in a variety of industries. AI applications are becoming more innovative and efficient thanks to these accelerators, which can improve computer vision tasks, deploy models more efficiently, and allow real-time inference on edge devices. Developers and researchers may unlock new possibilities and create meaningful AI solutions in the real world by harnessing the technical brilliance of AI-hardware accelerators, such as GPUs, and understanding their practical applications.